不等式约束优化问题
凸优化问题根据难度分为三层,不同难度的求解方法不同。第一层可以直接用KKT条件求解,第二层可以用牛顿法求解,以解决带有线性等式约束的优化问题。
本文要讲的内点法(interior-point method)位于第三层,进一步解决优化问题中的不等式约束,如下所示:
mins.t.f0(x)fi(x)≤0,i=1,⋯,mAx=b,(1)
其中f0,f1,⋯,fm:Rn→R是凸函数,且连续可微;对于A∈Rp×n,rankA=p<n。假设问题(1)可解,即最优解x∗存在。记f0(x∗)为f0∗。
假设:问题(1)严格可行(strictly feasible),即存在x∈D使得Ax=b,所有fi(x)<0成立。
KKT条件:
Ax∗=b,fi(x∗)λ∗∇f0(x∗)+i=1∑mλi∗∇fi(x∗)+ATν∗λi∗fi(x∗)≤0,i=1,⋯,m≥0=0=0,i=1,⋯,m.(2)
对数屏障
为解决问题(1),我们用罚函数将问题(1)近似为一个等式约束优化问题
mins.t.f0(x)+i=1∑nI−(fi(x))Ax=b,
其中,I−:R→R是非正实数的指标函数(indicator function),
I−(u)={0∞u≤0u>0.
对数屏障算法
定义对数屏障(logarithmic barrier)
ϕ(x)=−i=1∑mlog(−fi(x)),
其中定义域domϕ={x∈Rn∣fi(x)<0,i=1,⋯,m}要求不等式约束严格可行。
引入一个参数t>0,可以看出,t1ϕ(x)是I−(x)的近似。当t越大时,t1ϕ(x)对I−(x)的近似效果越好,如下图所示。实际求解优化问题过程中,可以通过每一步迭代增加t的值来达到更好的逼近效果,如:直接令t为迭代步数。
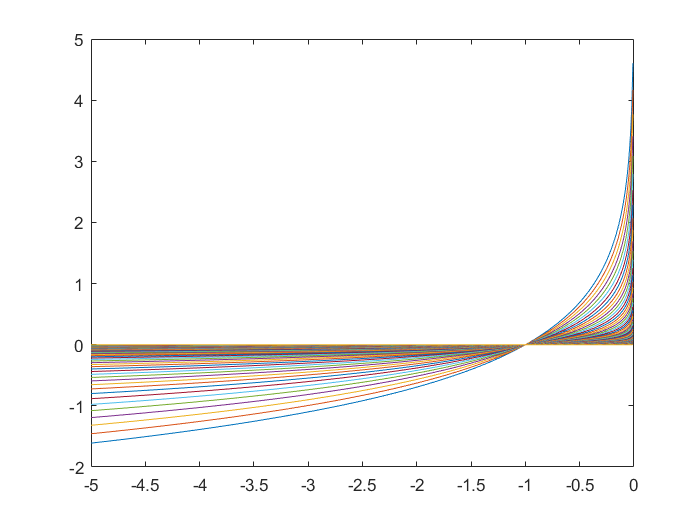
对数屏障函数ϕ(x)的梯度和Hessian分别为
∇ϕ(x)∇2ϕ(x)=i=1∑m−fi(x)1∇fi(x),=i=1∑nfi2(x)1∇fi(x)∇fiT(x)+i=1∑m−fi(x)1∇2fi(x).
令最优解为ϵ-optimal,则m/t=ϵ。算法描述如下:

中心路径
考虑优化问题
mins.t.tf0(x)+ϕ(x)Ax=b.(3)
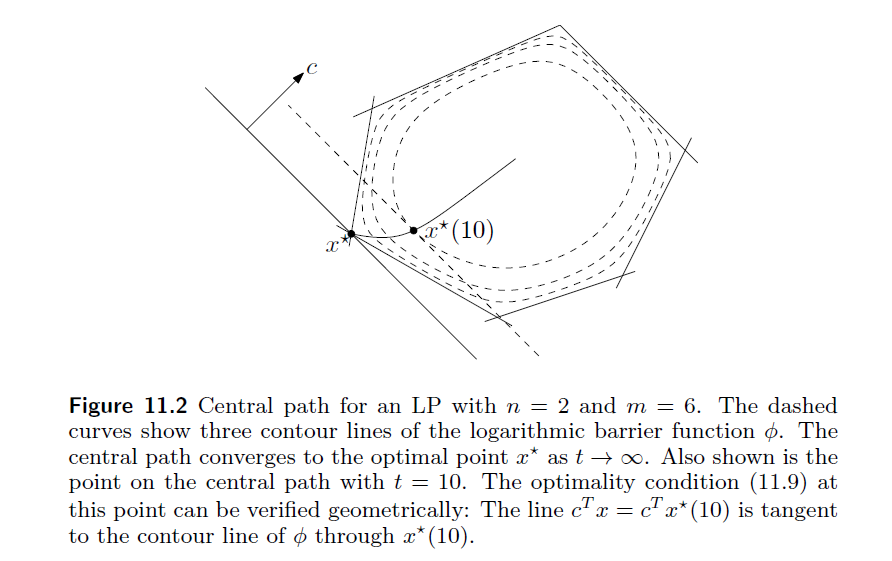
假设问题(3)能用牛顿法解决,且对于每一个t>0,问题(3)都有唯一解x∗(t)。问题(1)的中心路径(central path)即为中心点x∗(t)形成的集合。
点位于中心路径的充分必要条件(centrality condition)为:x∗(t)严格可行,且存在ν^∈Rp使得式(4)成立:
0=t∇f0(x∗(t))+∇ϕ(x∗(t))+ATν^=t∇f0(x∗(t))+i=1∑m−fi(x∗(t))1∇fi(x∗(t))+ATν^.(4)
由式(4)可以推出,每一个中心点产生一个对偶可行点。定义
λi∗(t)=−tfi(x∗(t))1,i=1,⋯,m,ν∗=tν^.
则称λ∗(t)、ν∗(t)对偶可行(dual feasible)。由centrality condition可知,λ∗(t)、ν∗(t)满足前面的KKT条件(2),故相应的x∗(t)也使得拉格朗日函数最小。
对偶函数g(λ∗(t),ν∗(t))有界,且
g(λ∗(t),ν∗(t))=f0(x∗(t))+i=1∑mλi∗(t)fi(x∗(t))+ν∗(t)T(ATx∗(t)−b)=f0(x∗(t))−m/t≤f0∗.
可知duality gap为m/t,且f0(x∗(t))−f0∗≤m/t,即x∗(t)至少是m/t-optimal的。
用改进KKT条件解释
改进KKT条件(modified KKT):对于近似的x∗(t),x=x∗(t)当且仅当存在λ,ν满足
Ax∗=b,fi(x∗)λ∗∇f0(x∗)+i=1∑mλi∗∇fi(x∗)+ATν∗−λi∗fi(x∗)≤0,i=1,⋯,m≥0=0=1/t,i=1,⋯,m.(5)
与式(2)对比,唯一不同的地方是λi∗fi(x∗)=0换成了−λi∗fi(x∗)=1/t。
例子:不等式线性规划
考虑LP
mins.t.cTxAx≤b.
对数屏障函数
ϕ(x)=−i=1∑mlog(bi−aiTx),domϕ={x∣Ax<b}.
centrality condition
tc+i=1∑nbi−aiTx1ai=0.
随着t增大,近似最优解逐渐接近真实最优解,形成的轨迹即为中心路径,如下图所示。
改进KKT条件与牛顿法的关系
牛顿法KKT系统
[t∇2f0(x)+∇2ϕ(x)AAT0][vnνn]=[−t∇f0(x)−∇ϕ(x)0]
将λi=−tfi(x)1代入改进KKT条件,解得v=vn,ν=νn/t。详见Boyd 2004章节11.3.4。
对数屏障算法的近似误差
以Mahyar 2018的时变优化问题为例。只考虑不等式约束
mins.t.f0(x,t)fi(x,t)≤0,i∈[p]
其最优解为
x∗(t)=x∈Rnargminf0(x,t)+i=1∑pI−(fi(x,t))(6)
用对数屏障函数近似的最优解为
x^∗(t)=x∈D^(t)argminf0(x,t)−c(t)1i=1∑plog(s(t)−fi(x,t))(7)
其中D^(t):={x∈Rn∣fi(x,t)<s(t),i∈[p]}。通过引入松弛变量s(t)保证初始时刻x(0)∈D^(0)。
假设1 (convexity):对任意t≥0,fi(x,t),i∈[p]是凸的,f0(x,t)是一致强凸的。
假设2 (Slater's Condition):可行域的内点非空,即存在x†使得fi(x†,t)<0,i∈[p]成立。
Lemma 1: Let x∗(t) and x^∗(t) be defined as in (6) and (7), respectively. Then, under Assumption 1 and 2, and for any λ∗∈Γ∗(t) and t≥0, the following inequality holds:
∣f0(x^∗(t),t)−f0(x∗(t),t)∣≤c(t)p+s(t)(λ∗∈Γ∗(t)inf∥λ∗∥1)
证明:定义
x~∗=x∈Rnargminf0(x,t)+i=1∑pI−(fi(x,t)−s(t))
通过扰动和灵敏度分析(Boyd 2004章节5.6),当s(t)≥0时,可建立如下不等式:
0≤f0(x∗(t),t)−f0(x~∗(t),t)≤i=1∑pλi∗s(t)(8)
前一个不等式是因为s(t)放松了可行域,最优值只会更小不会增加。后一个不等式直接由灵敏度分析得出(Boyd 2004章节5.6)。利用对数屏障函数−c1log(−u)替代指标函数I−(u),我们可以得到正上界(Boyd 2004章节11)
f0(x^∗(t),t)−f0(x~∗(t),t)≤c(t)p(9)
由(8)(9)可得,
∣f0(x^∗(t),t)−f0(x∗(t),t)∣≤c(t)p+i=1∑pλi∗s(t)≤c(t)p+s(t)(λ∗∈Γ∗(t)inf∥λ∗∥1)
定义
Φ(x,c,s,t)=f0(x,t)−c1i=1∑plog(s−fi(x,t))
给定prediction-correction算法
x˙=−∇xx−1Φ(P∇xΦ+∇xsΦs˙+∇xcΦc˙+∇xtΦ)(10)
要使用对数屏障算法,还需要证明x(t)∈D^(t)对所有t≥0成立。
Lemma 2: Let x^∗(t) be defined in (7) and x(t) be the solution of (10) for x(0)∈D^(0), s(0)>maxifi(x(0),0), and c(0)>0. Then, under Assumptions 1 and 2, x(t) satisfies x(t)∈D^(t) for all t≥0. Moreover, the following inequality holds:
∥x(t)−x^∗(t)∥≤C3e−αt
where 0≤C3:=mf1∥∇xΦ(x(0),c(0),s(0),0)∥≤0。
证明:因为f0是mf-强凸,c>0,Φ在D^(t)内也是mf-强凸。∇xxΦ−1存在且一致有界。将(10)代入闭环动力学,得∇˙xΦ=−α∇xΦ,因此∥∇xΦ∥是有界的。注意到
∇xΦ(x,c,s,t):=∇xf0(x,t)+c1i=1∑ps−fi(x,t)∇xfi(x,t),
即在D^(t)的边界上∥∇xΦ∥无界。因此由∥∇xΦ∥的有界性可以推出x(t)∈D^(t)。再由强凸性得到
∥x(t)−x^∗(t)∥≤mf1∥∇xΦ(x(t),c(t),s(t),t)∥
结合∇˙xΦ=−α∇xΦ得证。